Docker-compose 환경의 '어플리케이션 및 서버 모니터링' 스택 아키텍처
목차
- 용어 소개
- 요약
- On-Premise 모니터링 아키텍쳐
- (On-premise) 아키텍처 구성도
- (On-premise) 매트릭(metric) 모니터링 순서도
- (On-premise) 로그(metric) 모니터링 순서도
- Cloudwatch모니터링 아키텍처 소개
- (Cloudwatch) 아키텍처 구성도
- (Cloudwatch) 모니터링 순서도
- 구성 요소 소개
- 공통 구성 요소 소개
- 매트릭
- Node-exporter
- cAdvisor
- 로그
- docker log-driver
- 매트릭
- On-Premise 모니터링 구성 요소 소개
- Cloudwatch 모니터링 구성 요소 소개
- 공통 구성 요소 소개
1. 용어 소개
1) 매트릭(metric)
- 시스템 성능과 상태에 대한 통계적 정보
- 수치화 되어 나타남
- (서버) CPU 사용량
- (서버) 메모리 사용량
- (컨테이너별) CPU 사용량
- (컨테이너별) 메모리 사용량
- (컨테이너별) 응답 시간
- 매트릭의 예시 (Prometheus 자체 metric들)

2) 로그(log)
- 시스템과 어플리케이션 내부에서 발생한 이벤트 / 정보를 기록한 데이터
- API 호출 및 응답 기록
- 어플리케이션 실행 / 종료
- 오류 발생 여부
- 로그의 예시 (hadoop 로그)
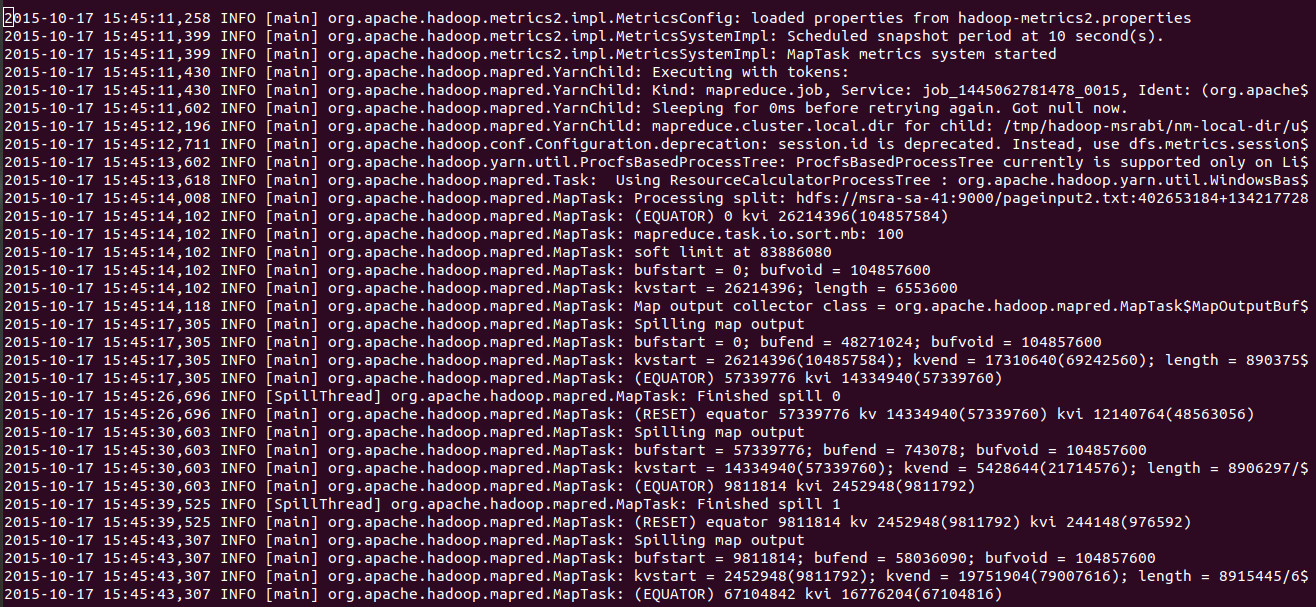
2. 요약
1) 모니터링 순서 전반
(1) 매트릭 모니터링 과정
- 매트릭 수집 > 매트릭 집계 > 매트릭 전송 > 매트릭 저장 > 매트릭 시각화
- 집계: 수집된 매트릭의 메타데이터(label, tag, etc...)를 변경하거나 추가, 삭제하는 기능
- 전송: 매트릭 집계 어플리케이션과 매트릭 저장 어플리케이션이 다를 경우, 집계된 매트릭을 매트릭 저장 어플리케이션에 전달하는 과정.
(2) 로그 모니터링 과정
- 로그 수집 > 로그 집계 > 로그 전송 > 로그 저장 > 로그 시각화
- 집계: 수집된 로그의 메타데이터(label, tag, etc...)를 변경하거나 추가, 삭제하는 기능
- 전송: 로그 집계 어플리케이션과 로그 저장 어플리케이션이 다를 경우, 집계된 로그를 로그 저장 어플리케이션에 전달하는 과정.
2) 서버 상태(매트릭) 모니터링 구성
| 환경 | 수집 | 집계 | 전송 | 저장 | 시각화 |
|---|---|---|---|---|---|
| On-premise | Node exporter | Prometheus | - | Prometheus (local TSDB) |
Grafana |
| Cloudwatch | Cloudwatch Agent | Cloudwatch Agent | Cloudwatch Agent > CloudWatch | CloudWatch | CloudWatch |
3) 컨테이너 상태(매트릭) 모니터링 구성
| 환경 | 수집 | 집계 | 전송 | 저장 | 시각화 |
|---|---|---|---|---|---|
| On-premise | cAdvisor | Prometheus | - | Prometheus (local TSDB) |
Grafana |
| Cloudwatch | cAdvisor | Telegraf | Telegraf > Cloudwatch | Cloudwatch | Cloudwatch |
4) 컨테이너 로그 모니터링 구성
| 환경 | 수집 | 집계 | 전송 | 저장 | 시각화 |
|---|---|---|---|---|---|
| On-premise | Docker Log driver | Docker Log driver | Docker Log driver > Loki | Loki (local TSDB or Object storage) |
Grafana |
| Cloudwatch | Docker Log driver | Docker Log driver | Docker Log driver > Cloudwatch | Cloudwatch | Cloudwatch |
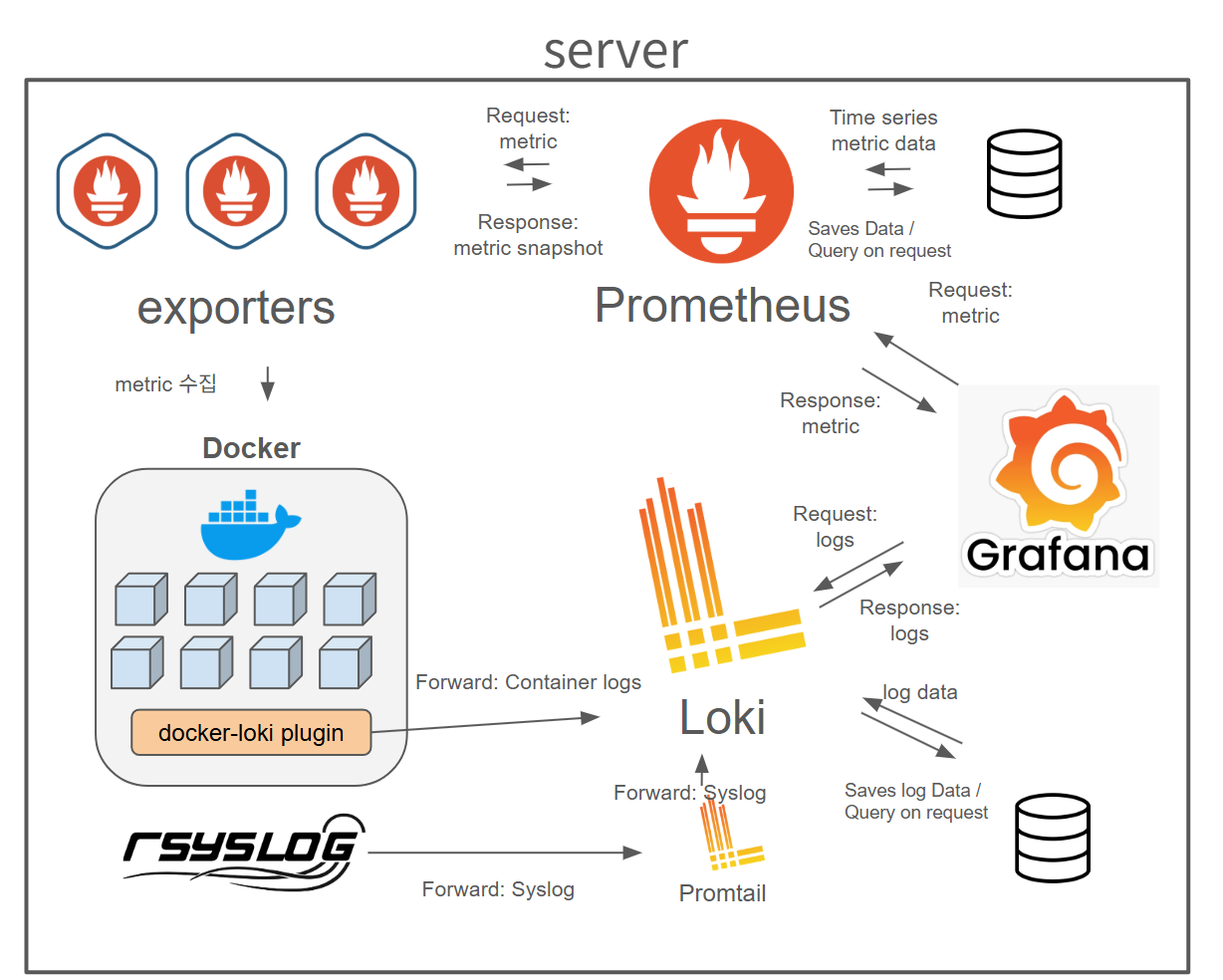
2) 아키텍쳐 구성도 (on-premise)
- On-premsie 서버와 일부 AWS서버 등에서 사용중인 아키텍쳐.
- PLG(Prometheus + Loki + Grafana) 스택을 사용함
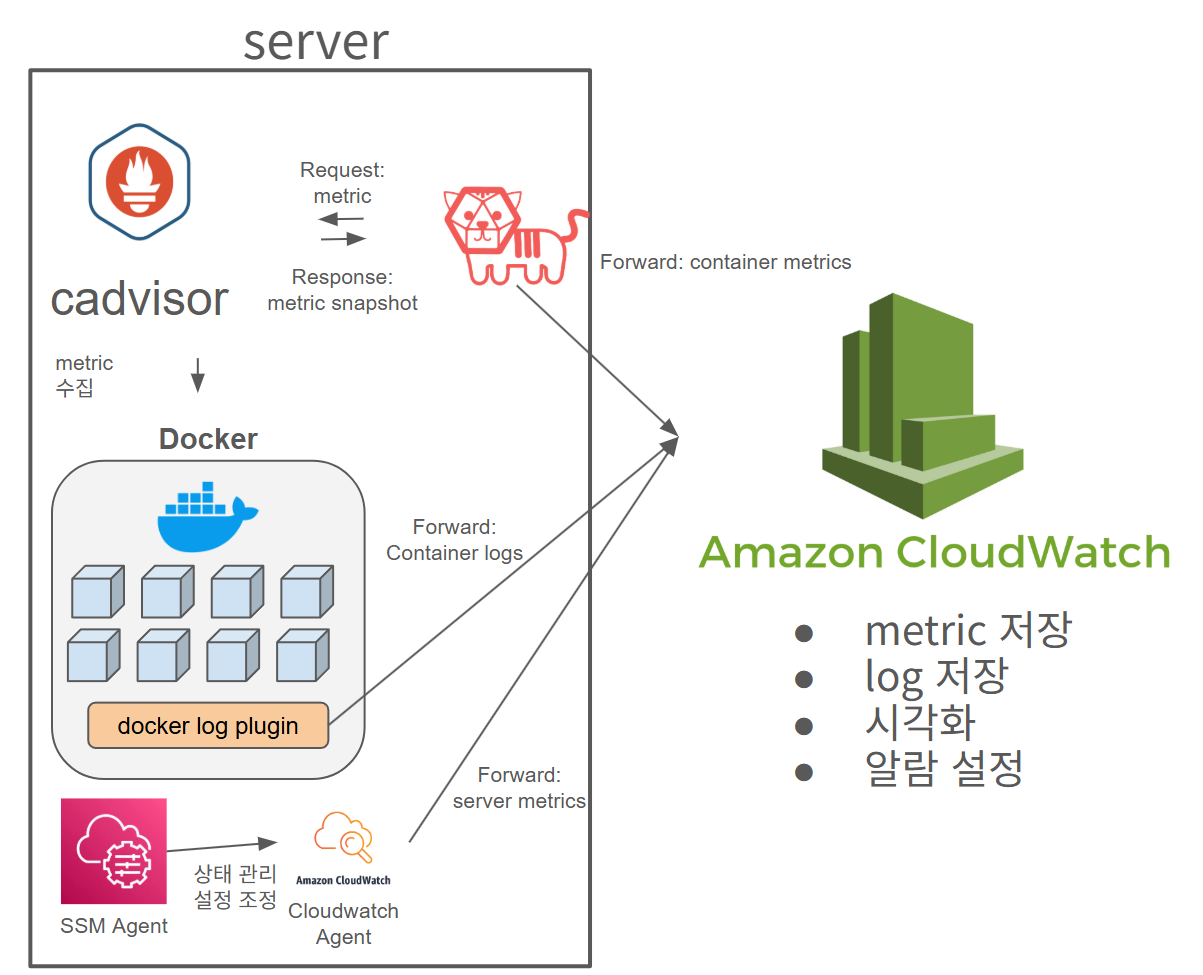
3) 아키텍쳐 구성도 (AWS)
- 일부 AWS 서버에서 사용 예정인 아키텍쳐.
- Telegraf + Cloudwatch Agent + Cloudwatch 를 사용함.
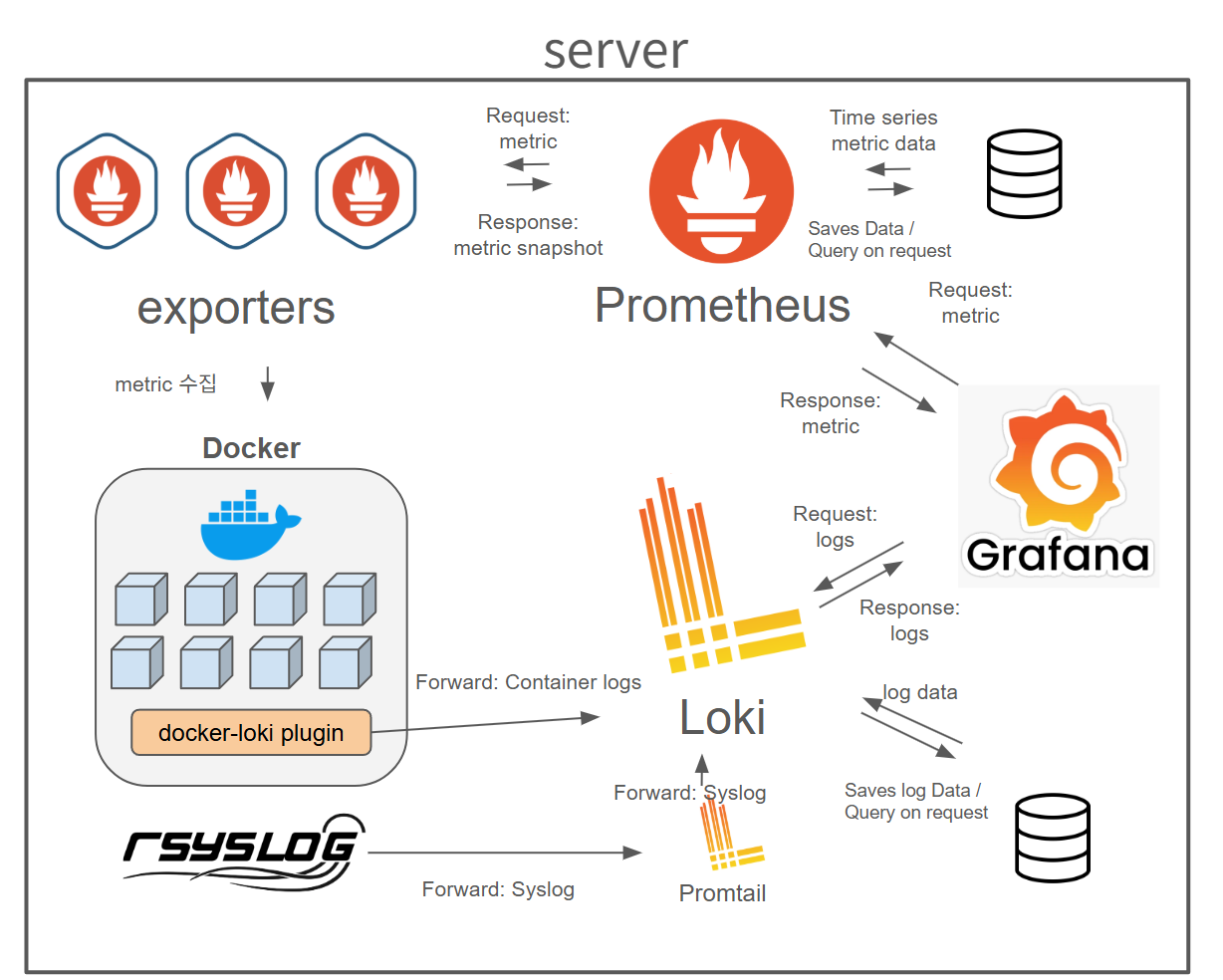
3. On-Premise 모니터링 아키텍쳐
1) 아키텍쳐 소개
2) 매트릭(metric) 모니터링 순서도
(1) 매트릭(metric) 수집 순서
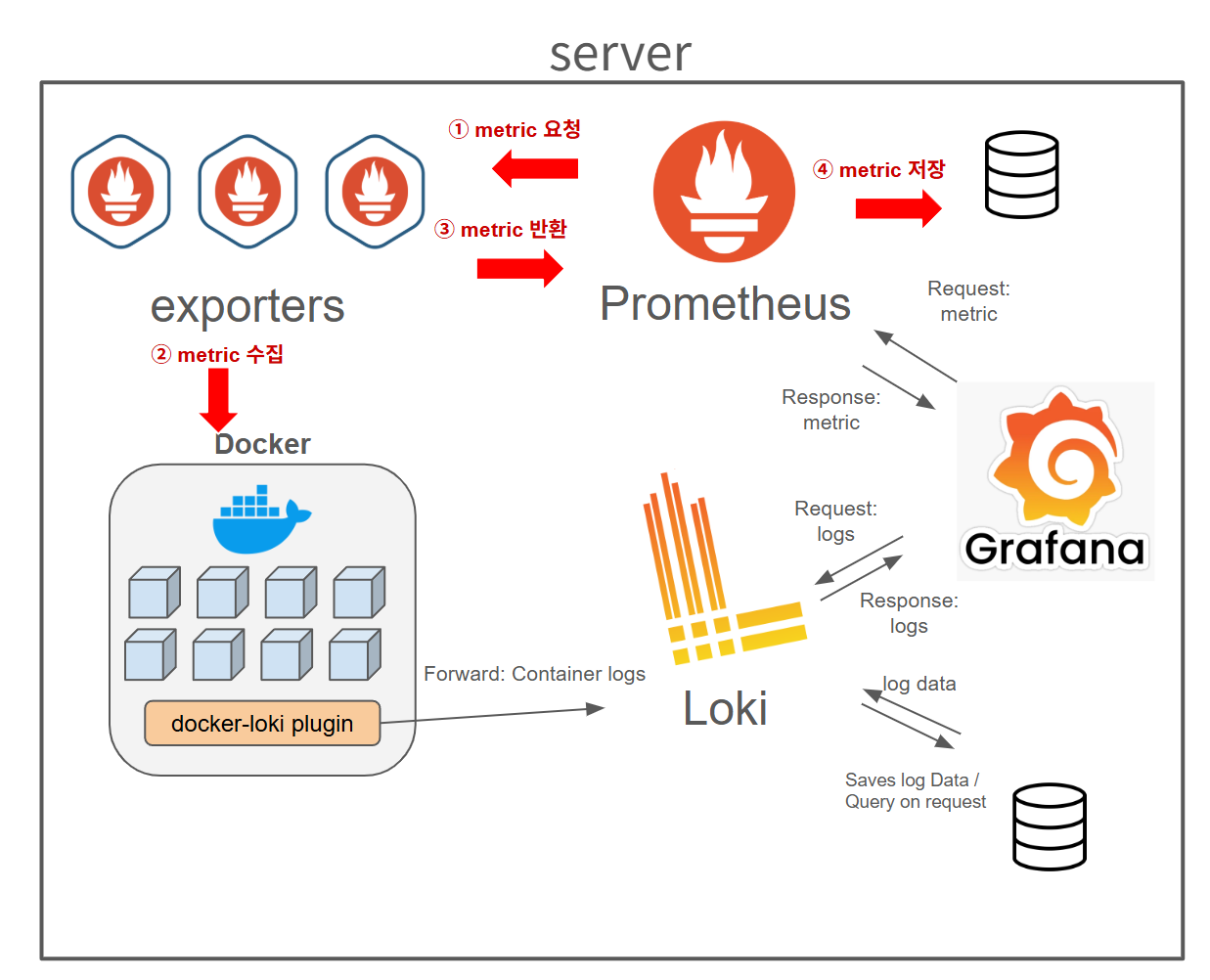
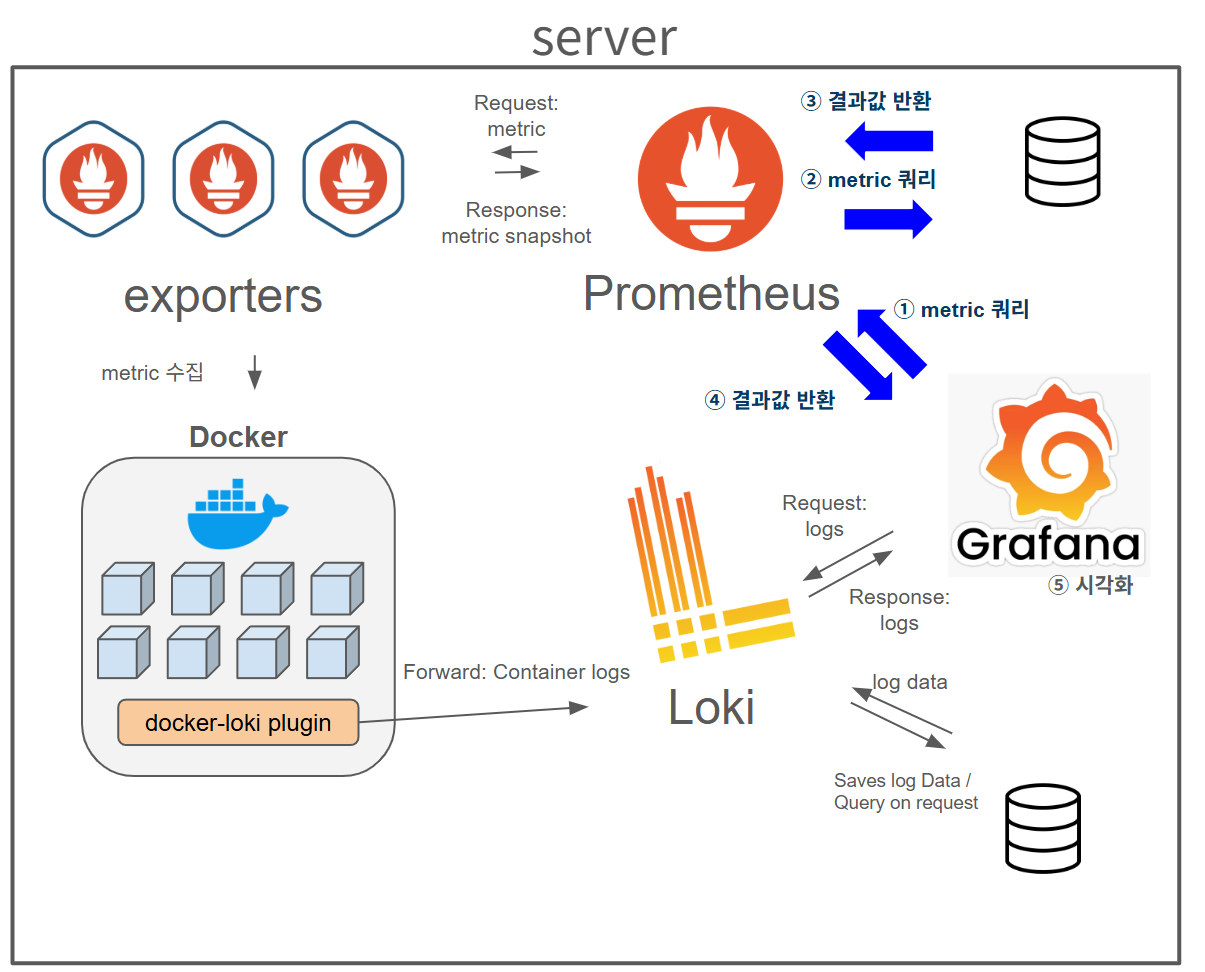
(2) 매트릭(metric) 시각화 순서
3) 로그(log) 모니터링 순서도
(1) 로그(log) 수집 순서
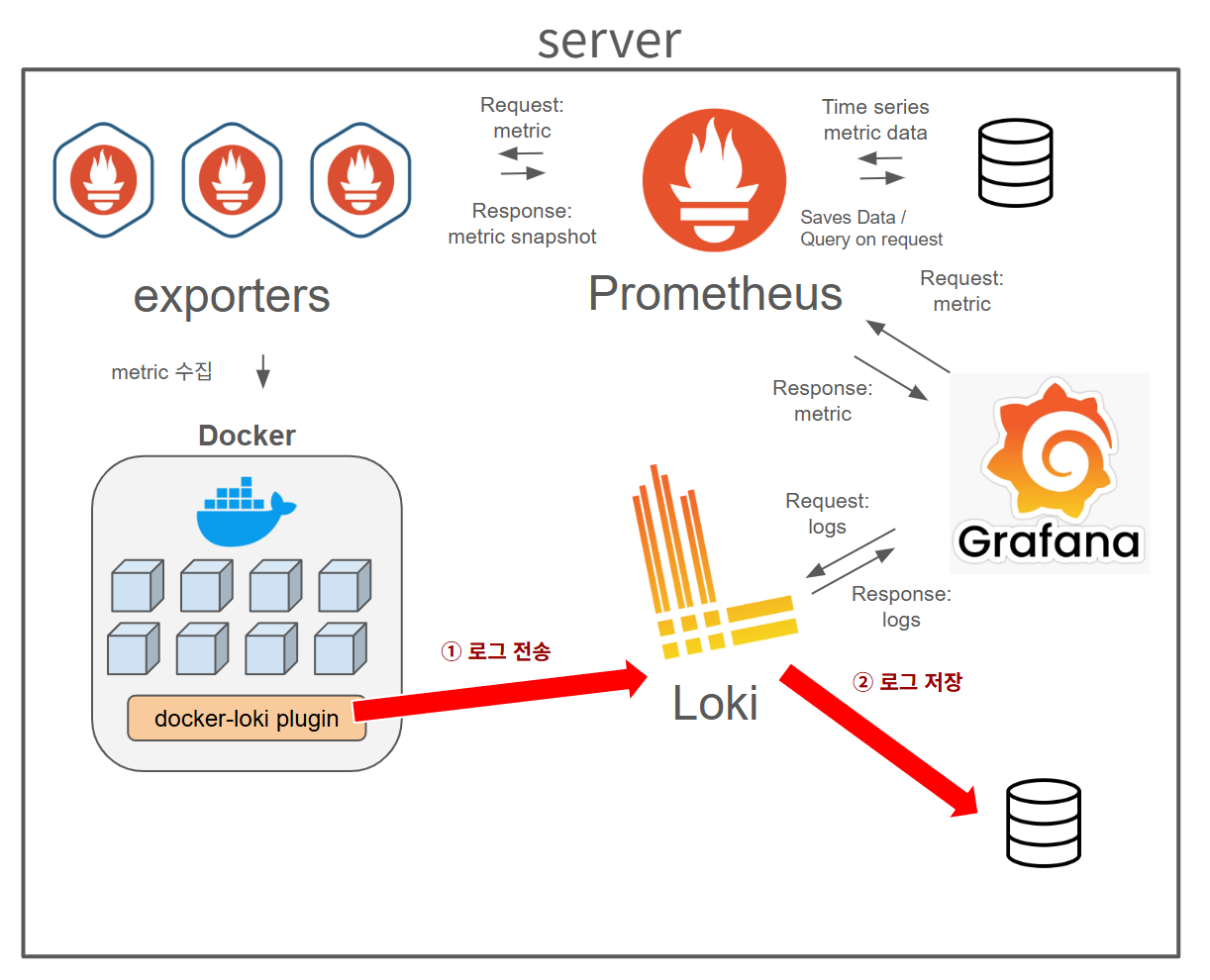
(2) 로그(log) 시각화 순서

4. Cloudwatch 모니터링 아키텍쳐
1) 아키텍쳐 소개

2) 순서도

5. 상세 구성 요소 소개
1) 공통
(1) 매트릭
a. Node-exporter (서버 상태 수집기)
- 설치된 서버의 CPU 사용량, 메모리 사용량, Disk IO 등의 매트릭을 수집함.
- http request 를 받을 때 매트릭 수집을 시작, response 로 수집된 매트릭을 반환함.
- Prometheus exporter 중 하나. 수집한 metric을 prometheus metric 포맷으로 반환.
# node-exporter 컨테이너의 설정 예시. 기본적인 path 설정 외 추가 설정 필요 없음.
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter-${CUST_NM}
restart: always
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
mem_limit: 2g
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
- '--collector.processes'b. cadvisor (컨테이너 상태 수집기)
- 설치된 서버에서 구동중인 컨테이너의 CPU 사용량, 메모리 사용량, Disk IO 등의 매트릭을 수집함.
- http request 를 받을 때 매트릭 수집을 시작, response 로 수집된 매트릭을 반환함.
- Prometheus exporter 중 하나. 수집한 metric을 prometheus metric 포맷으로 반환.
# cadvisor 컨테이너의 설정 예시. 기본적인 path 설정 외 추가 설정 필요 없음.
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor-${CUST_NM}
ports:
- published: 8080
target: 8080
restart: always
mem_limit: 2g
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /home/docker/lib/docker:/var/lib/docker:ro # 도커 실행 위치(2) 로그
a. docker log-driver
- Docker 에서 구동되는 서비스와 컨테이너들의 정보를 얻어올 수 있는 매커니즘들의 모음.
local file,fluntd,awslog등의 다양한 드라이버 제공
https://docs.docker.com/engine/logging/configure/
- 설정 예시 (1) - aws cloudwatch 로 log 전송
{ "log-driver": "awslogs", "log-opts": { "awslogs-region": "ap-south-1", "awslogs-group": "india-docker-compose", "awslogs-create-group": "true", "tag": "{{.Name}}" }, "data-root": "/home/docker/lib/docker", "default-ulimits": { "core": { "Name": "core", "Hard": 0, "Soft": 0 } } }- 설정 예시 (2) - Local 환경에서 실행중인 Loki 로 log 전송
{ "log-driver": "loki", "log-opts": { "loki-url": "http://localhost:3100/loki/api/v1/push", "loki-batch-size": "400" }, "data-root": "/home/docker/lib/docker", "default-ulimits": { "core": { "Name": "core", "Hard": 0, "Soft": 0 } } }
2) On-premise
(1) 매트릭
a. Prometheus
- 소개: 매트릭 수집 / 시각화 / 알림 등을 제공하는 오픈소스 모니터링 프로그램
- 대표 기능:
- pull 방식으로 매트릭을 수집, 시계열 데이터 저장
- PromQL을 활용해 저장된 시계열을 쿼리 및 집계
- 특이사항
- local filesystem 을 활용하는 TSDB가 포함됨.
- Prometheus 만으로는 고가용성 확보 / 장기적 데이터 보관 어려움.
- 고가용성 확보 위해서는 Thanos (+ Obeject storage) 등의 어플리케이션 필요.
# extend-compose
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus-${CUST_NM}
volumes:
- ${VOLUME_HOME}/${CUST_NM}/prometheus/volume:/prometheus # 해당 디렉토리 하위에 TSDB가 위치함. write 권한 부여 필요.
- ./prometheus.yml:/etc/prometheus/prometheus.yml # 설정 파일 주소
mem_limit: 2g
ports:
- 19090:9090 # 외부 19090: 내부 9090
command: # web.enalbe-lifecycle은 api 재시작없이 설정파일들을 reload 할 수 있게 해줌
- '--web.enable-lifecycle'
- '--config.file=/etc/prometheus/prometheus.yml'
restart: always# prometheus-config.yaml 파일
global:
scrape_interval: 15s # 타겟들로부터의 metric 수집 주기 / default = 1m
scrape_timeout: 15s # 타겟들로부터의 request time out 대기 시간/ default = 10s
evaluation_interval: 2m # 사용자가 설정한 role을 새로 읽어들이는 주기 / default = 1m
external_labels:
monitor: 'default-monitor' # 기본적으로 붙여줄 라벨
query_log_file: query_log_file.log # prometheus의 쿼리 로그들을 기록, 없으면 기록안함
# 규칙을 로딩하고 'evaluation_interval' 설정에 따라 정기적으로 평가한다.
rule_files:
- "prometheus-rule.yml" # prometheus.yml 과 동일 위치
# 매트릭을 수집할 엔드포인드. 여기선 Prometheus 서버 자신을 가리킨다.
scrape_configs:
# 이 설정에서 수집한 타임시리즈에 `job=<job_name>`으로 잡의 이름을 설정한다.
# metrics_path의 기본 경로는 '/metrics'이고 scheme의 기본값은 `http`다
- job_name: 'monitoring-item' # job_name 은 모든 scrap 내에서 고유해야함
scrape_interval: 10s # global에서 default 값을 정의해주었기 떄문에 안써도됨
scrape_timeout: 10s # global에서 default 값을 정의해주었기 떄문에 안써도됨
metrics_path: '/metrics' # 옵션 - prometheus가 metrics를 얻기위해 참조하는 URI를 변경할 수 있음 | default = /metrics
honor_labels: false # 옵션 - 라벨 충동이 있을경우 라벨을 변경할지설정(false일 경우 라벨 안바뀜) | default = false
honor_timestamps: false # 옵션 - honor_labels이 참일 경우, metrics timestamp가 노출됨(true일 경우) | default = false
scheme: 'http' # 옵션 - request를 보낼 scheme 설정 | default = http
# 실제 scrap 하는 타겟에 관한 설정
static_configs:
- targets: ['prometheus:19090', 'cadvisor:8080', 'loki:3100','node-exporter:9100']
labels: # 옵션 - scrap 해서 가져올 metrics 들 전부에게 붙여줄 라벨
service : 'monitor-1'- 참고: Prometheus 아키텍쳐 구성(in Docker)
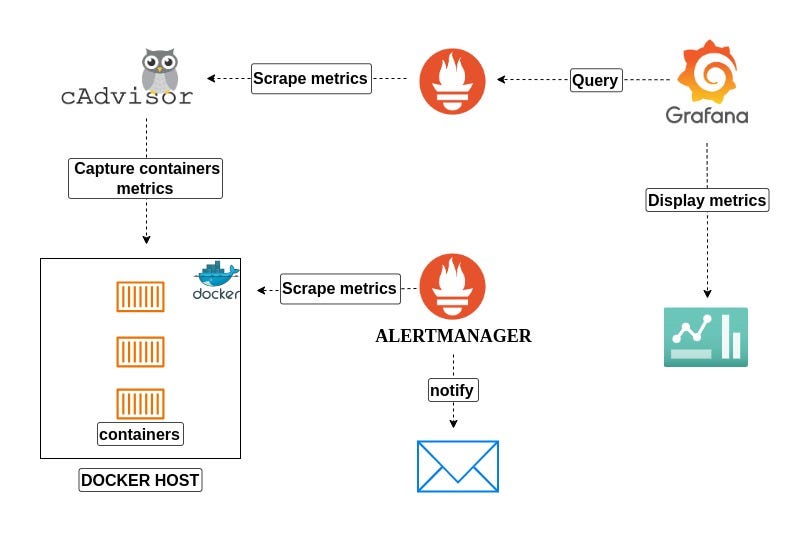
https://medium.com/@pateldivya/docker-monitoring-a-comprehensive-guide-to-prometheus-grafana-cadvisor-nodeexporter-and-294df21e806b
(2) 로그
a. Loki
- 소개: 로그 수집 / 시각화 / 알림 등을 제공하는 오픈소스 모니터링 프로그램
- 대표 기능:
- 로그를 수집 및 저장
- logQL(PromQL과 거의 동일한 문법)을 활용해 로그가 저장된 시계열을 쿼리 및 집계
- 특이사항
- Object storage가 있을 경우, loki 자체적으로 고가용성 확보 가능
- Docker-compose 모니터링 케이스에서는 monolithic deployment + Local filesystem DB 기반으로 운용.
# Loki 설정 예시
loki:
image: grafana/loki:latest
container_name: loki-${CUST_NM}
volumes:
- ./loki-config.yml:/etc/loki/loki-config.yml:ro # 설정 파일
- ${VOLUME_HOME}/${CUST_NM}/loki/:/tmp/loki # log 데이터 저장하는temp 영역. write 권한 부여 필요
- ${VOLUME_HOME}/${CUST_NM}/loki/data/retention:/data/retention # tmp에 저장된 데이터를 압축하여 저장하는 여역. write 권한 부여 필요
- /var/run/docker.sock:/var/run/docker.sock:ro # docker socket 위치
ports:
- protocol: tcp
published: 3100 # http listen port (default)
target: 3100 # http listen port (default)
- 9096:9096 # default grpclb port
- 9095:9095 # default grpc listen port
restart: always
command: -config.file=/etc/loki/loki-config.yml(3) 시각화
a. Grafana
- 소개: 수집된 metric / log를 시각화하여 보여주는 오픈소스 도구.
- 대표 기능
- 대시보드 활용한 metric / log 열람
- 알람 설정
- 구성 요소
- Datasource
- Grafana에서 시각화할 metric / log 정보를 갖고 있는 어플리케이션들.
- 참고: Grafana 자체는 metric / log 정보를 저장하지 않음.
- ex) Prometheus, Loki, Cloudwatch, PostgreSQL, XDB-N 등
- Grafana에서 시각화할 metric / log 정보를 갖고 있는 어플리케이션들.
- DB:
- Grafana 대시보드, user 정보 등을 저장하는 db.
- default: sqlite3.
- Datasource
- 중요: Grafana 자체는
어떠한 종류의 metric/log도저장하지 않음.- 신규 Grafana 구성 시 모니터링 원하는 데이터를 수집/저할 방안을 함께 구성해야 함
# Grafana 설정 예시
grafana:
image: grafana/grafana:latest
container_name: grafana-${CUST_NM}
ports:
- 3000:3000 # 외부 3000: 내부 3000
volumes:
- ${VOLUME_HOME}/${CUST_NM}/grafana/volume:/var/lib/grafana # write 권한 부여 필요
restart: always
mem_limit: 2g
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:19090
jsonData:
timeInterval: "5s"
environment: # Dooray email 알람설정 예시
- GF_SMTP_ENABLED=false3) Cloudwatch
(1) 매트릭
a. Telegraf
- 소개: DB, 시스템, 및 IoT 센서에서 메트릭 및 이벤트(로그) 를 수집하고 전송하기 위한 플러그인 중심 서버 에이전트
- 단일 바이너리로 컴파일되어 동작.
- 대표 기능
- 다양한 종류의 input 에서 동시에 data를 수집할 수 있음.
- 다양한 format으로부터의 데이터 수집을 native하게 지원하는 것이 장점.
- ↔ Prometheus - Prometheus exporter 와 일부 prometheus-navtive 한 metric을 제공하는 어플리케이션들에서만 데이터를 수집할 수 있음.
- input 예시: cpu(local), memory(local), ping, PostgreSQL, http, Prometheus exporters....
- 다양한 format으로부터의 데이터 수집을 native하게 지원하는 것이 장점.
- 다양한 종류의 Output 으로 수집한 data를 저장할 수 있음.
- 데이터를 저장하는 다양한 방식을 native하게 지원하는 것이 장점.
- ↔ Prometheus: local filesystem db만 지원
- output 예시: S3, Cloudwatch, Prometheus, PostgreSQL, filesystem, http....
- 데이터를 저장하는 다양한 방식을 native하게 지원하는 것이 장점.
- 다양한 종류의 input 에서 동시에 data를 수집할 수 있음.
# telegraf의 docker image 설정 예시
telegraf:
image: telegraf:1.28
container_name: telegraf
restart: unless-stopped
network_mode: "host"
user: root
volumes:
- ./telegraf.conf:/etc/telegraf/telegraf.conf:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
environment:
- AWS_REGION=ap-south-1# telegraf.conf 내용
# Global agent configuration
[agent]
interval = "60s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "15s"
flush_jitter = "0s"
precision = ""
hostname = ""
omit_hostname = false
# debug = true
# input - cAdvisor
[[inputs.prometheus]]
urls = ["http://localhost:8080/metrics"]
namepass = [
"container_cpu_usage_seconds_total",
"container_memory_usage_bytes",
"container_network_receive_bytes_total",
"container_network_transmit_bytes_total"
]
# tag 내용 변경
[[processors.rename]]
[[processors.rename.replace]]
tag = "container_label_com_docker_compose_service"
dest = "app_name"
# Output - Cloudwatch
[[outputs.cloudwatch]]
region = "${AWS_REGION}"
namespace = "DockerContainerMetrics"
taginclude = ["app_name"](2) 기타
a. Cloudwatch(AWS 서비스)
- 소개: AWS내 오브젝트들의 매트릭, 로그 등을 수집하고 이를 시각화하거나 알람을 설정할 수 있는 서비스
- 자세한 설명은 AWS 공식 문서 참고
- 대표 기능
- 매트릭 수집 / 저장
- 로그 수집 / 저장
- 시각화
- 대시보드 생성
- 알람 설정
- 기타
- 구성 요소
- SSM Agent - EC2(VM)에 설치됨. 사용자가 AWS Dashboard 내에서 Cloudwatch Agent 설정을 변경할 수 있게 함.
- Cloudwatch Agent - EC2(VM)에 설치됨. 각종 metric이나 log를 수집할 수 있음.
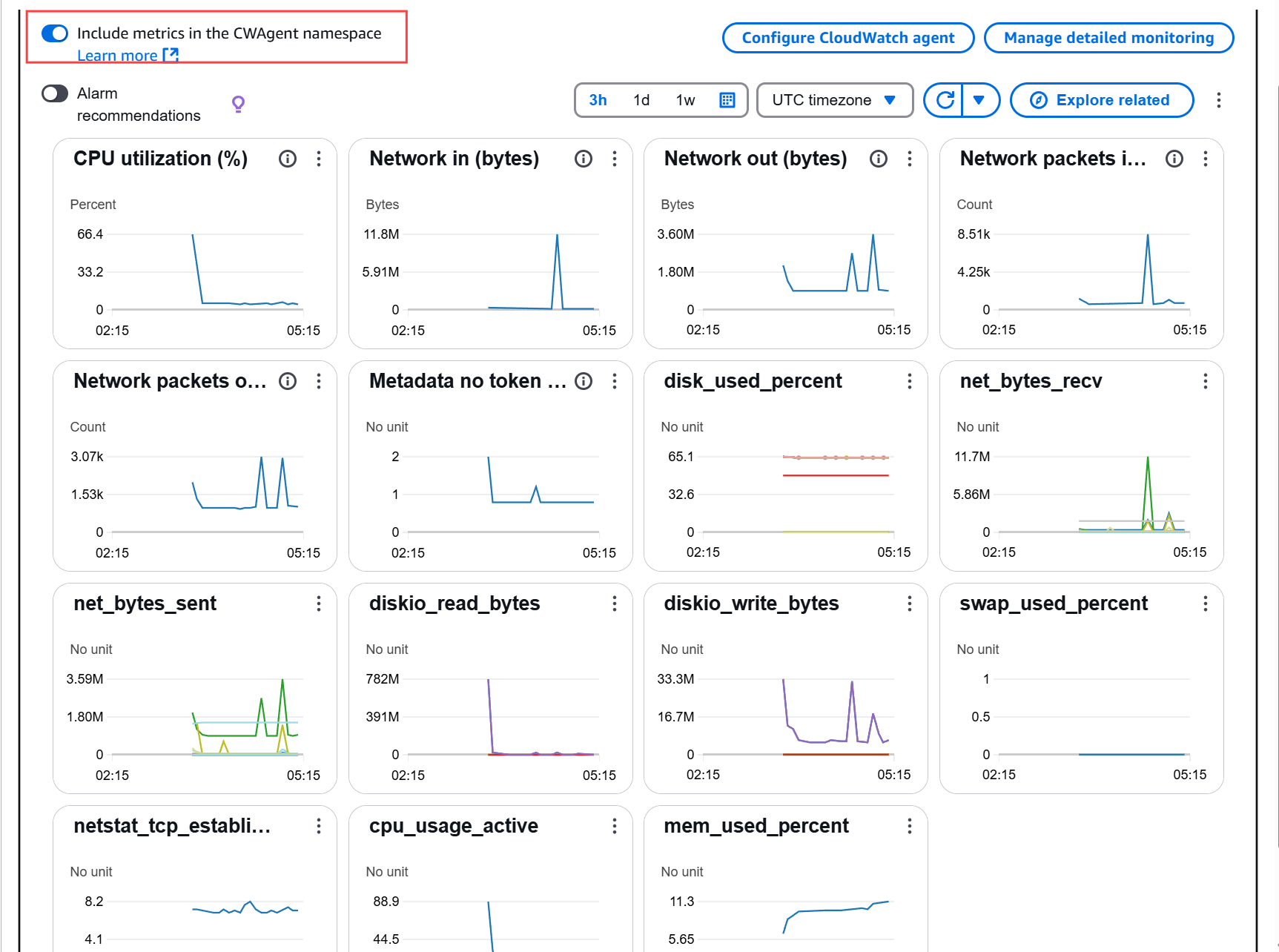
- 샘플 사진
'TIL > Monitoring(k8s, grafana)' 카테고리의 다른 글
| [Grafana, K8s, helm] grafana sidecard를 활용한 dashboard provisioning in k8s (0) | 2025.04.29 |
|---|---|
| Telegraf 를 활용한 Prometheus exporter metric 수집 및 DB 적재 (0) | 2025.03.04 |
| [RKE2] Grafana 의 ingress (0) | 2025.02.28 |
| Prometheus - exporter들의 정확성 테스트 (0) | 2025.02.21 |
| [모니터링, k8s]RKE2 기반 k8s 모니터링 (0) | 2025.02.21 |